
This blog was arranged with the assistance of using Le Chat from Mistral.AI.
Bandits: A Clever Approach to Decision Making in Machine Learning…with some inevitable side effects
Imagine you’re in a casino, standing in front of a row of slot machines (often called “one-armed bandits”). Each machine has a different probability of paying out, but you don’t know which one is the best. Your goal is to maximize your winnings, but how do you decide which machine to play?
You might start by trying each machine a few times to get an idea of which ones are more likely to pay out (this is called exploration). Once you have some data, you might focus more on the machines that seem to give the best rewards (this is called exploitation). The challenge is balancing between exploring enough to find the best machine and exploiting the best machine you’ve found so far to maximize your winnings (so simply the basic conceptual ideas of capitalism).
This scenario is a classic illustration of the multi-armed bandit problem, a fundamental concept in machine learning that deals with making sequential decisions under uncertainty.
What Are Bandits?
The term “bandit” comes from the analogy of slot machines, which are sometimes colloquially referred to as “one-armed bandits” because they can take all your money if you’re not careful. In machine learning, the multi-armed bandit problem is a framework for addressing the exploration-exploitation trade-off.
Key Concepts in Bandit Problems
- Arms:
- These are the different choices or actions you can take. In the slot machine analogy, each arm corresponds to a different slot machine. In a real-world scenario, arms could represent different ads to display, different content recommendations, or different treatments in a clinical trial.
- Rewards:
- When you choose an arm (take an action), you receive a reward. For example, if an ad is clicked, you receive a reward (e.g., revenue from the click). If a recommended video is watched for a long time, that could be considered a high reward.
- Exploration vs. Exploitation:
- Exploration: Trying out different arms to gather more information about their expected rewards.
- Exploitation: Choosing the arm that has given the highest average reward so far to maximize immediate payoff.
- The core challenge is finding the right balance between exploration and exploitation.
- Regret:
- A measure of how much better you could have done if you always chose the best arm (with the highest expected reward) from the start. The goal is to minimize regret over time (until you regret you ever played with the bandits).
Why Are Bandits Important in Machine Learning?
Bandit problems are a special case of reinforcement learning where the goal is to learn from interactions with an environment to make decisions that maximize cumulative reward. They are particularly useful in scenarios where you need to make decisions sequentially and learn from feedback to improve future decisions.
Applications of Bandit Algorithms
- Online Advertising:
- Selecting which ad to show to a user to maximize click-through rates. The bandit algorithm explores different ads and exploits the ones that perform best.
- Content Recommendation:
- Recommending articles, videos, or products to users based on their past interactions. The goal is to maximize engagement by balancing between showing popular items and exploring new ones.
- Clinical Trials:
- Assigning patients to different treatments to find the most effective one while minimizing the number of patients receiving suboptimal treatments.
- A/B Testing:
- Efficiently testing different versions of a webpage or app feature to determine which one performs best without requiring extensive testing periods.
- Resource Allocation:
- Deciding how to allocate limited resources (e.g., servers, network bandwidth) to different tasks to maximize overall efficiency.
Types of Bandit Algorithms
There are several strategies to solve bandit problems, each with its own approach to balancing exploration and exploitation:
- Epsilon-Greedy:
- Choosing an arm in the epsilon-greedy method is like deciding whether to stick with a familiar restaurant or try a new one. With a probability of 1−ϵ (exploitation), you go to the restaurant you know you like (the arm with the highest average reward). With a probability of ϵ (exploration), you choose a new, random restaurant to try (a random arm), even though you don’t know if it’s good.
- This method is simple because it’s easy to understand the core idea: sometimes you go with what you know works, and other times you take a chance to find something even better. However, it’s not always the most efficient strategy. For example, if you find an excellent new restaurant, this method will still sometimes force you to try other random restaurants, even if they’re not as promising.
- Thompson Sampling:
- The Thompson Sampling method is like being a detective with a hunch. Instead of just picking the arm with the highest average reward, you have a belief about how good each arm could be. This belief is represented as a range of possibilities, not just a single number.
- At each step, you “imagine” the best-case scenario for each arm by randomly picking a value from its range of possibilities. Then, you choose the arm that has the best imagined value. If an arm hasn’t been tried much, its range of possibilities is broad, so it has a good chance of being picked to be explored. If an arm has been tried many times and consistently gives good rewards, its range of possibilities is narrow and high, making it a strong candidate for exploitation.
- This way, the algorithm naturally focuses on exploring arms that are more uncertain but have the potential for high rewards while also exploiting arms that have a proven track record. It’s a more intuitive and efficient way to balance exploration and exploitation than just choosing randomly.
- Upper Confidence Bound (UCB):
- Think of the Upper Confidence Bound (UCB) method as being a cautiously optimistic gambler. Instead of just looking at an arm’s average reward (how much it’s paid out so far), you also consider how uncertain you are about its true value.
- You calculate an “optimism score” for each arm. This score is a combination of its average reward and a bonus for how little you’ve tried it. The bonus is bigger for arms you haven’t played much because you’re still very uncertain about their potential.
- At each step, you simply choose the arm with the highest optimism score. This means you’ll either pick the arm that has the best track record (exploitation) or a less-played arm that has a high potential to be better (exploration). The algorithm naturally favors exploring arms that have high uncertainty, as they represent the biggest “unknown unknowns” that could lead to a massive payoff.
- Contextual Bandits:
- Imagine you’re recommending an article to a user. Instead of just picking the one that’s been most popular in the past, you also consider who the user is (their age, interests, what they’ve read before) and what the article is about (its topic, author, length).
- This is the core idea of contextual bandits. It’s like having a more informed gambling machine. You’re not just pulling a lever blindly; you’re using extra clues to make a smarter decision. For each user, you use their specific information (the context) to predict which arm (article) is most likely to give a high reward (a click or a read).
Example: Choosing Between Ads
Let’s consider a practical example of using bandits in online advertising:
- Arms: Different ads that can be shown to users.
- Rewards: Whether a user clicks on the ad (click-through rate).
- Exploration: Show different ads to gather data on their effectiveness.
- Exploitation: Show the best-performing ad more frequently to maximize clicks.
Using a bandit algorithm like Thompson Sampling, the system can dynamically adjust which ads to show based on observed click-through rates, balancing the need to explore new ads and exploit the best-performing ones.
Implementing Bandits
Here’s a simple example of how to implement an epsilon-greedy bandit algorithm in Python:
import numpy as np
class Bandit:
def __init__(self, num_arms, epsilon=0.1):
self.num_arms = num_arms
self.epsilon = epsilon # Number of times each arm was pulled self.counts = np.zeros(num_arms) # Estimated value of each arm self.values = np.zeros(num_arms)
def select_arm(self):
if np.random.rand() < self.epsilon:
# Explore: choose a random arm
return np.random.randint(self.num_arms)
else:
# Exploit: choose the arm with the highest estimated value
return np.argmax(self.values)
def update(self, chosen_arm, reward):
# Update the count and estimated value for the chosen arm
self.counts[chosen_arm] += 1
n = self.counts[chosen_arm]
value = self.values[chosen_arm]
# Update the estimated value using incremental averaging
self.values[chosen_arm] = value + (reward - value) / n
# Example usage
num_arms = 3
bandit = Bandit(num_arms)
# Simulate pulling arms and receiving rewards
for _ in range(1000):
chosen_arm = bandit.select_arm()
# Simulate reward: let's assume arm 0 has a higher mean reward
reward = np.random.normal(0.5 if chosen_arm == 0 else 0, 1)
bandit.update(chosen_arm, reward)
print("Estimated values for each arm:", bandit.values)
print("Number of pulls for each arm:", bandit.counts)In this example, the bandit algorithm learns that arm 0 has a higher expected reward and exploits this knowledge to maximize cumulative rewards over time.
Conclusion
Bandit problems provide a powerful framework for decision-making under uncertainty. By balancing exploration and exploitation, bandit algorithms can efficiently learn which actions yield the best rewards without requiring extensive prior knowledge. This makes them particularly useful in real-world applications like online advertising, content recommendation, and resource allocation.
Understanding and implementing bandit algorithms can help you make smarter decisions in dynamic environments, optimizing for long-term rewards rather than short-term gains. Whether you’re a data scientist, machine learning engineer, or simply curious about decision-making algorithms, bandits offer an intuitive and effective approach to sequential decision-making.
Bandits in Social Media: The Double-Edged Sword
In our previous section, we introduced the concept of bandit algorithms as a clever approach to decision-making under uncertainty. We saw how these algorithms can efficiently balance exploration and exploitation to optimize outcomes in various applications, from online advertising to clinical trials.
But what happens when these powerful algorithms are applied to social media platforms? On one hand, bandit algorithms can enhance user experience by personalizing content and recommendations. On the other hand, they can also lead to unintended and harmful consequences, as vividly depicted in the documentary “The Social Dilemma.”
The Power of Bandits in Social Media
Social media platforms are a perfect application for bandit algorithms. Here’s how they are typically used:
- Content Personalization:
- Social media platforms use bandit algorithms to decide which posts, videos, or articles to show in a user’s feed. The goal is to maximize user engagement, measured by likes, shares, comments, and time spent on the platform.
- Each piece of content is an “arm,” and the algorithm learns which types of content generate the most engagement for each user.
- Advertisement Optimization:
- Similarly, bandit algorithms help determine which advertisements to display to which users to maximize click-through rates and conversions.
- This allows platforms to optimize ad revenue while also providing users with ads that are relevant to their interests.
- Notification Strategies:
- Platforms use bandit algorithms to decide when and how to send notifications to users to maximize engagement without causing too much annoyance.
- Different notification strategies (timing, content, frequency) are the arms, and the reward is user engagement following the notification.
The Dark Side: Bandits and the Social Dilemma
While bandit algorithms can improve user experience and engagement, their use in social media also raises significant ethical concerns. These concerns are at the heart of “The Social Dilemma,” a documentary that explores the unintended consequences of social media algorithms on society (unintended but widely accepted consequences).
1. Addiction and Mental Health
Bandits and Addiction:
- Bandit algorithms are designed to maximize engagement, often by showing users content that evokes strong emotional reactions. This can lead to addictive behaviors as users become conditioned to seek out these emotional triggers.
- The constant stream of engaging content can contribute to anxiety, depression, and other mental health issues, particularly among adolescents and young adults.
Example:
- A bandit algorithm might learn that a particular user engages more with videos that evoke strong emotional responses, such as outrage or excitement. The algorithm will then prioritize showing similar content to keep the user engaged, potentially leading to addiction and negative mental health outcomes.
2. Echo Chambers and Polarization
Bandits and Echo Chambers:
- Personalization algorithms, including bandits, tend to show users content that aligns with their existing beliefs and preferences. This creates echo chambers where users are exposed only to information that reinforces their existing views.
- Over time, this can lead to increased societal polarization, as people become less exposed to diverse viewpoints and more entrenched in their own beliefs.
Example:
- If a user frequently engages with content that supports a particular political viewpoint, the bandit algorithm will prioritize showing similar content. This can reinforce the user’s beliefs and contribute to a polarized society where people with different viewpoints struggle to understand each other.
3. Spread of Misinformation
Bandits and Misinformation:
- Content that is sensational or controversial often generates more engagement, as it elicits strong emotional reactions. Bandit algorithms, which aim to maximize engagement, may inadvertently prioritize such content.
- This can lead to the rapid spread of misinformation and fake news, as these types of content often generate high levels of engagement.
Example:
- During elections, misinformation and sensationalist content can spread rapidly due to the engagement-driven nature of bandit algorithms. This can undermine democratic processes by misleading voters and amplifying divisive content.
4. Exploitation of Vulnerable Populations
Bandits and Vulnerability:
- Bandit algorithms may exploit vulnerabilities in certain populations. For example, adolescents and individuals with mental health issues may be more susceptible to addictive content and misinformation.
- By maximizing engagement without considering the potential harm, these algorithms can exacerbate issues like anxiety, depression, and self-harm behaviors.
Example:
- If a vulnerable user frequently engages with content related to self-harm or eating disorders, the bandit algorithm may continue to show similar content, potentially exacerbating the user’s condition.
5. Privacy Concerns
Bandits and Privacy:
- Effective personalization and recommendation systems rely on extensive data collection about users’ behaviors, preferences, and personal information.
- This raises significant privacy concerns, as users may not be fully aware of the extent of data collection or the ways in which their data is being used.
Example:
- Social media platforms collect vast amounts of data on user interactions, which are used to train bandit algorithms. This data can include sensitive information about users’ personal lives, preferences, and vulnerabilities.
Addressing the Ethical Concerns
Given the significant ethical concerns surrounding the use of bandit algorithms in social media, it is crucial to explore potential solutions and mitigations:
1. Ethical AI Design
Principle: Incorporate ethical considerations into the design and implementation of AI systems from the outset.
Actions:
- Develop algorithms that prioritize user well-being and societal good alongside engagement metrics.
- Implement safeguards to prevent the spread of harmful or misleading content.
- Use fairness-aware algorithms to ensure that recommendations do not disproportionately favor certain groups or viewpoints.
2. Transparency and Accountability
Principle: Ensure that AI systems are transparent and accountable to users and society at large.
Actions:
- Provide clear and accessible explanations of how algorithms work and how they influence the content users see.
- Allow users to see and adjust the data that is being collected about them.
- Establish independent oversight bodies to audit and regulate AI systems.
3. User Empowerment
Principle: Empower users to make informed choices about their social media use and the content they consume.
Actions:
- Provide tools and settings that allow users to customize their feeds and limit exposure to certain types of content.
- Offer educational resources to help users understand the potential impacts of social media on their mental health and well-being.
- Implement features that encourage healthy usage patterns, such as screen time limits and reminders.
4. Regulatory Oversight
Principle: Establish robust regulatory frameworks to govern the use of AI and data collection in social media.
Actions:
- Implement data protection laws that give users control over their personal information and how it is used.
- Enforce transparency requirements for AI systems used in social media platforms.
- Create regulations that limit the use of exploitative or manipulative algorithms.
5. Public Awareness and Advocacy
Principle: Raise public awareness about the ethical implications of AI-driven social media and advocate for responsible practices.
Actions:
- Support research and public discourse on the societal impacts of AI and social media.
- Advocate for policies and practices that prioritize user well-being and societal good.
- Encourage ethical practices within the tech industry through advocacy and public pressure.
Conclusion: Balancing Innovation and Responsibility
Bandit algorithms are a powerful tool for decision-making under uncertainty, and their application in social media platforms has revolutionized how content and advertisements are personalized and delivered. However, as depicted in “The Social Dilemma,” these algorithms also pose significant ethical and societal challenges.
By understanding the potential harms and implementing strategies to mitigate them, we can harness the benefits of bandit algorithms while minimizing their negative impacts. It is crucial for technology developers, policymakers, and society at large to work together to ensure that AI-driven systems are designed and used in ways that prioritize user well-being, societal good, and ethical considerations.
As we continue to innovate and develop more sophisticated algorithms, we must also remain vigilant about their broader impacts on society. By doing so, we can create a future where technology enhances our lives without compromising our well-being and democratic values.
That was of course, a summary created by a balanced AI. I don’t see that the politicians, but also society at large really want to work on the many negative side effects of the bandit exploration and exploitation system. That’s terrible.
Bandits explained by YouTube
YouTube’s recommendation system is one of the most advanced and largest-scale industrial recommender systems existing, serving billions of users and processing hundreds of billions of data points daily. At the core of its functionality is a sophisticated interplay between deep neural networks and bandit algorithms, which together enable personalized video
recommendations that maximize user engagement. The following text provides a comprehensive technical and ethical analysis of YouTube’s bandit system and recommendation engine, focusing on how these components integrate to present new videos to users, the challenges they address, and the implications of their design.
High-Level Architecture of YouTube’s Recommendation System
YouTube’s recommendation engine is structured as a multi-stage pipeline designed to
efficiently narrow down millions of videos to a personalized set of recommendations for each
user. The architecture consists primarily of two deep neural networks: one for candidate
generation and another for ranking.
Candidate Generation Network: This network processes user activity history and
contextual features to retrieve a subset of hundreds of videos from YouTube’s vast
corpus of over 800 million videos. The goal is to efficiently filter out irrelevant content
and focus on videos that are likely to be of interest to the user. This stage leverages
collaborative filtering and embeddings learned from user behavior and video metadata
to capture complex relationships and similarities between users and videos. (1 2 3 4).
Ranking Network: The ranking network takes the candidate videos and assigns each a
score based on a rich set of features, including video metadata, user engagement
history, and contextual signals. This network predicts metrics such as expected watch
time and user satisfaction to prioritize the most relevant and engaging videos. The final
recommendations are then filtered for content quality, diversity, and appropriateness
before being presented to the user 1 2 3 4
Bandit Systems in YouTube’s Recommendation Engine
Bandit algorithms are fundamental to YouTube’s ability to balance exploration and exploitation in its recommendations. Originating from the multi-armed bandit problem, these algorithms enable the system to make decisions under uncertainty by continuously learning from user feedback.
Role of Bandits: YouTube uses bandit algorithms to decide when to show new or less
popular videos (exploration) versus videos known to maximize engagement
(exploitation). This balance is critical to maintaining user satisfaction and engagement
over time, as it prevents the system from getting stuck in a local optimum of only
recommending popular content 5 6 7.
Types of Bandits: The ε-greedy algorithm is a classic example used in YouTube’s
system, where with probability ε, the system explores a new video, and with probability
1-ε, it exploits the best-known video. Other variants, such as Upper Confidence Bound
(UCB) and Thompson Sampling, may also be employed to optimize the trade-off
between exploration and exploitation in different contexts 5 8.
Contextual Bandits: YouTube’s system integrates contextual information—such as user
features (e.g., demographics, past behavior) and video features (e.g., metadata,
embeddings)—into the bandit framework. This allows the algorithm to make more
informed decisions tailored to the specific user and video context, improving
recommendation relevance and engagement 5 9.
Integration with Neural Networks: The bandit algorithms work in concert with the neural
networks in the candidate generation and ranking stages. The neural networks provide
the contextual embeddings and predictions that inform the bandit’s decision-making,
enabling a dynamic and adaptive recommendation strategy 7 2.
This integration allows YouTube to continuously refine its recommendations based on realtime user feedback, ensuring that the system remains responsive to changing user
preferences and content trends 7.
Neural Networks in YouTube’s Recommendation Engine
Neural networks are the backbone of YouTube’s ability to process vast amounts of data and
extract meaningful patterns for personalized recommendations.
Neural Network Models: YouTube employs deep neural networks (DNNs), recurrent
neural networks (RNNs), and transformers to model user behavior and video features.
These models are capable of learning high-dimensional embeddings that capture
complex relationships between users and videos, enabling accurate predictions of user
preferences 1 2.
Training and Inference: The neural networks are trained on hundreds of billions of
examples using distributed training techniques. This massive scale allows the models to
generalize well across diverse user behaviors and video characteristics. During
inference, the models assign scores to videos based on user features and contextual
information, enabling real-time personalized recommendations.1 2
Personalization: Neural networks incorporate user history, preferences, and
engagement metrics to tailor recommendations. They learn embeddings that represent
user interests and video attributes, facilitating the matching of users to relevant content.
This personalization is crucial for maintaining user engagement and satisfaction 1 2.
Handling Fresh Content and Cold Start: The system uses natural language processing
(NLP) and word embeddings to address the cold-start problem for new videos with
limited behavioral data. By analyzing textual metadata, YouTube can infer content
similarity and recommend new videos to interested users without relying solely on past
user interactions.4
The neural networks’ ability to process and learn from vast datasets enables YouTube to
continuously improve its recommendations, adapting to user feedback and evolving content trends.2
Technical Design and Implementation
YouTube’s recommendation system is engineered to scale and operate in real-time, handling billions of users and videos with high efficiency.
Scalability: The system uses distributed training and serving infrastructure to manage
the computational complexity and data volume. This allows YouTube to train models with
approximately one billion parameters on hundreds of billions of examples and serve
recommendations with low latency.1 2
Real-Time Processing: Efficient algorithms and data structures enable real-time
candidate generation and ranking. The system processes user interactions and
contextual information on the fly, ensuring that recommendations are responsive and
relevant to the current user session 1236
Feedback Loops: User feedback—such as watch time, likes, dislikes, and survey
responses—is continuously incorporated into the system. This feedback refines the
models and bandit algorithms, enabling the system to adapt to changing user
preferences and improve recommendation quality over time.1 10
Quality Assurance: YouTube implements diversity and novelty metrics to ensure a
balanced mix of popular and niche content. The system also filters out inappropriate or
low-quality content to maintain user satisfaction and platform integrity.2 11
This technical design supports YouTube’s goal of delivering engaging, personalized, and high-quality recommendations at scale while remaining responsive to user behavior and content.
Finally, a diagram
That was a lot of text, and I suppose many will not make it until here, but I come from the last millennium when it was more common to write texts without many diagrams, but I know that was some time ago.
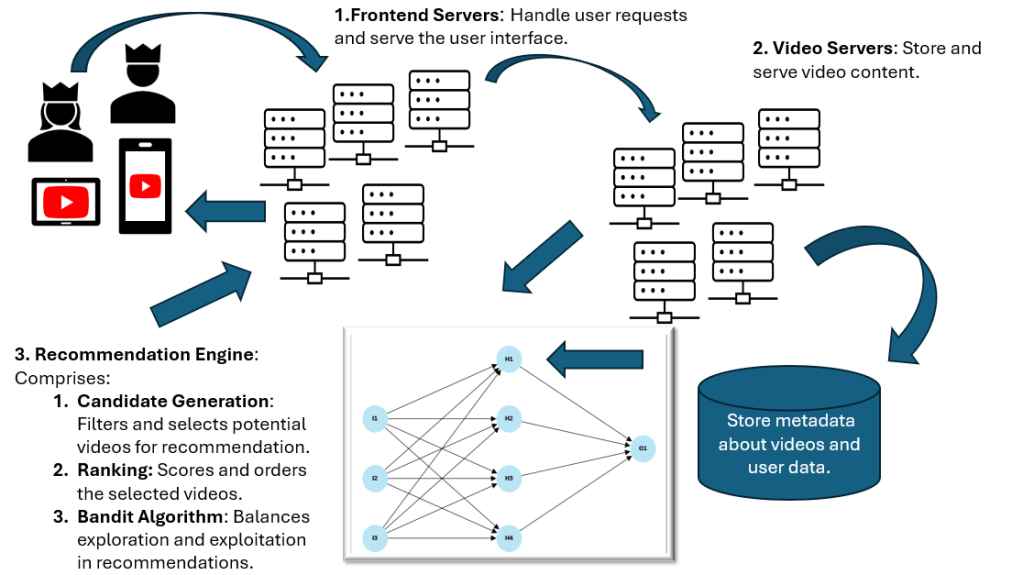
I don’t know whether you can understand it by this diagram, but anyhow it’s a little difficult to capture this complex system in one sketch.
But what I knew was that there was probably something that could do it much better than me: I asked PowerPoint’s CoPilot to make nice slides about the YouTube architecture. I passed to CoPilot some prompts from Mistral.AI, and within 20 seconds I got 20 professional-looking slides with excellent content about all that is mentioned in this blog focused on the YouTube system.
That reminds me, for a crucial part of my job description, it is, besides programming, to make such nice presentations about complex technical systems. But to compete with something that can do it in 20 seconds might be difficult. So I wait for my universal income that the guys from Silicon Valley promised, and I trust them…not really.
Final (human) conclusion
I am a member of the beginning generations, born in 1966, who were used to full airtime on television. Though not exactly in my childhood and beginning youngster time, television stopped at midnight with the national anthem and started somewhere at lunch sending in between a test picture. But apart from that I could watch a lot of TV from my childhood on. The major difference to the concept above was no one really knew what you had watched. If you wanted to watch critical and even cynical things about society, you watched at a late time. But if you had watched something at all, no one knew except the people in your household.
You had to talk about it, and that we did of course. We had very meaningful discussions, e.g. about why JR Ewing had again shaken things up in Dallas, and enjoyed many discussions around that. Hopefully some elder people at least will remember that time without looking it up on Google. It was a totally different time, and after writing this blog I really ask myself whether this time was ever true.
But it was foreseeable that this time would change. At the end of the seventies, video recorders and computer games gave the users a first chance to personalize their viewing experience.
Regarding YouTube, I really liked my personalized videos. I have seen their incredible content (the word content in this context no one would have understood in the eighties or earlier). But the problem is obvious: we are creating sophisticated, personalized bubbles and losing more and more contact with each other day by day.
Will there be meaningful regulation by authorities on a local, state, regional, or global level? I don’t think so.
But you personally can do it and find out how beautiful this world is without social media. Of course it is much more difficult for young people than for me who was raised in a totally different age. But I tell you it’s worth a try at least reducing the airtime on social media.
- Deep Neural Networks for YouTube Recommendations
- “Cracking the Code: Unveiling the Magic Behind YouTube’s Recommendation Algorithm” | by Sneh Shah | Medium
- Deep neural networks for YouTube recommendations | PPT
- How YouTube’s Recommendation System Works – Particular Audience
- Bandits for Recommender Systems
- What are bandit algorithms and how are they used in recommendations?
- The YouTube Algorithm: How It Works in 2025 | by Amit Yadav | Medium
- Vinija’s Notes • Recommendation Systems • Multi-Armed Bandits
- Understanding Social Media Recommendation Algorithms | Knight First Amendment Institute
- YouTube’s recommendation algorithm is unresponsive to user feedback, according to Mozilla | MIT Technology Review
- YouTube Recommendations Reinforce Negative Emotions
- Systematic review: YouTube recommendations and problematic content – PMC
- Algorithmic radicalization – Wikipedia
- Nudging recommendation algorithms increases news consumption and diversity on YouTube | PNAS Nexus | Oxford Academic
- Exploring YouTube’s Advanced Recommendation System for Enhanced User Engagement
- On YouTube’s recommendation system – YouTube Blog
